Novel View Synthesis of Transparent Object from a Single Image
------------------------------------------------------------------------------View Synthesis Results------------------------------------------------------------------------------
New Environment Maps |
||
 |
 |
 |
| Real Transparent Objects | ||

| Table 1. Results using 3D objects in ShapeNet and our new environment maps. | |||||
| Ground Truth | 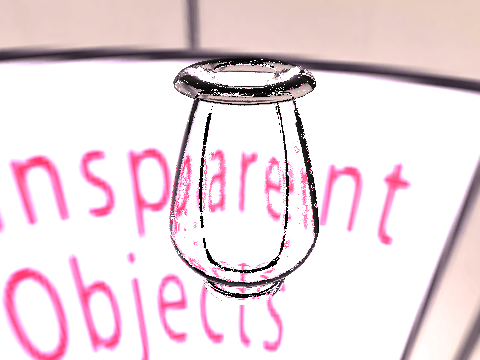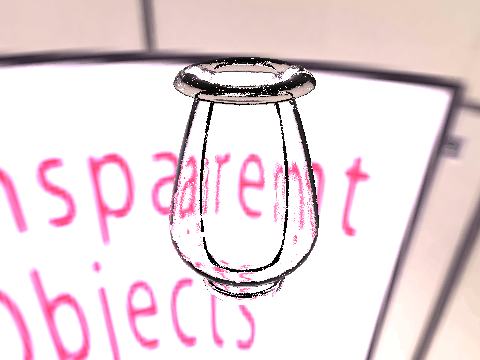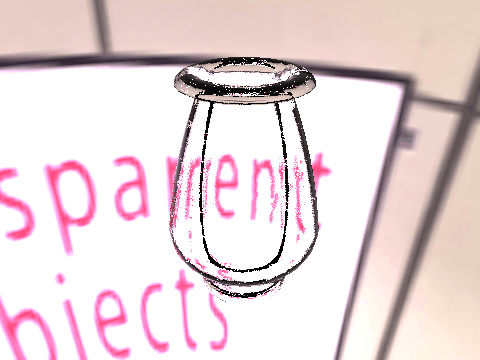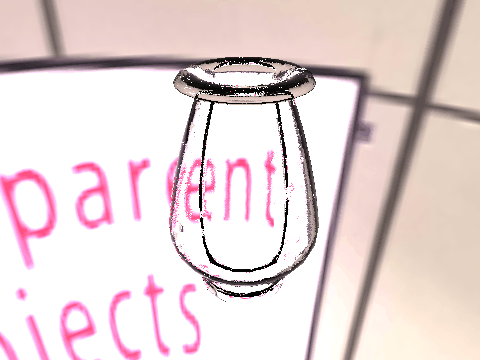 |
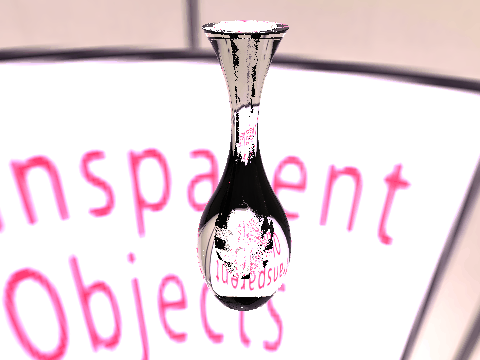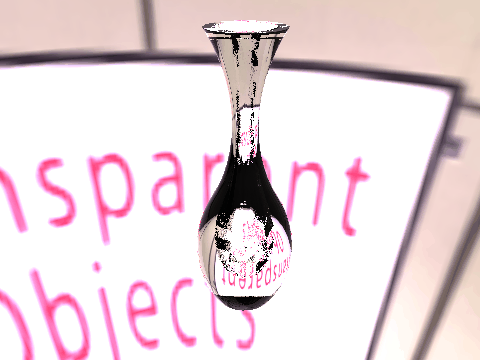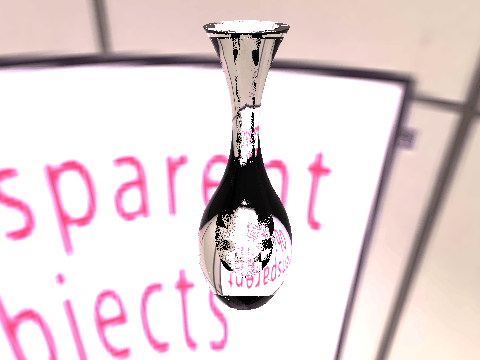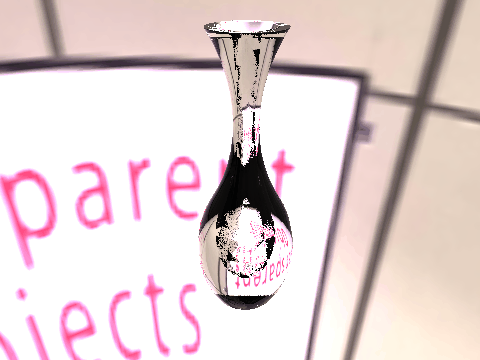 |
 |
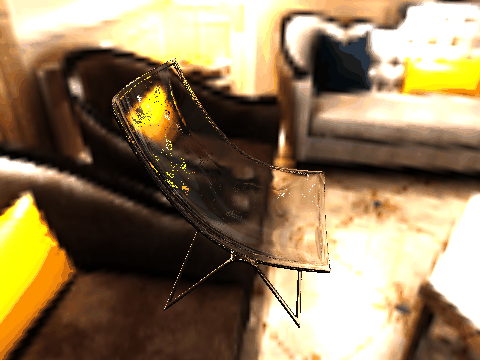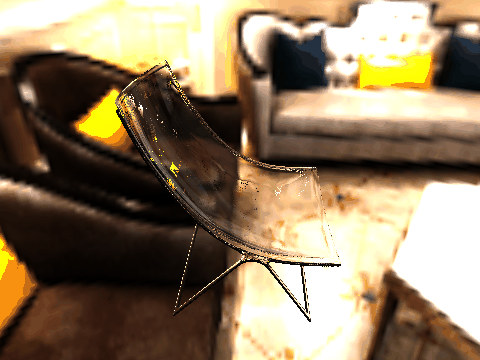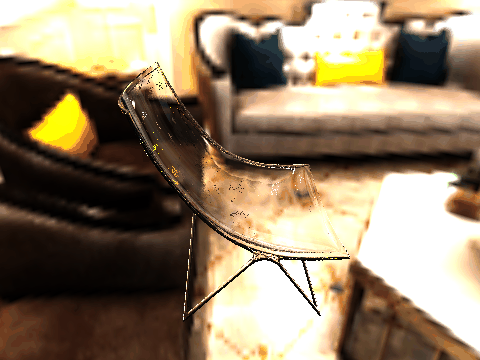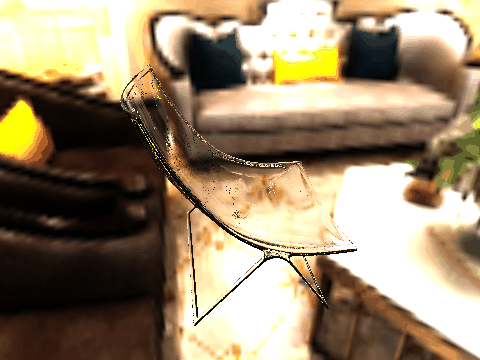 |
 |
| Results | 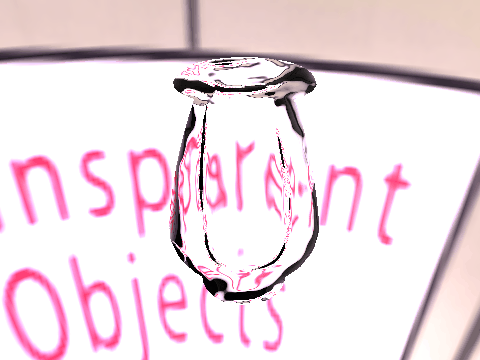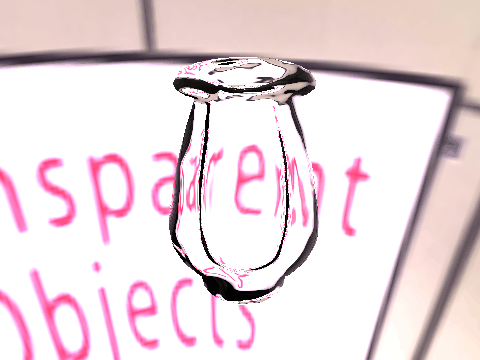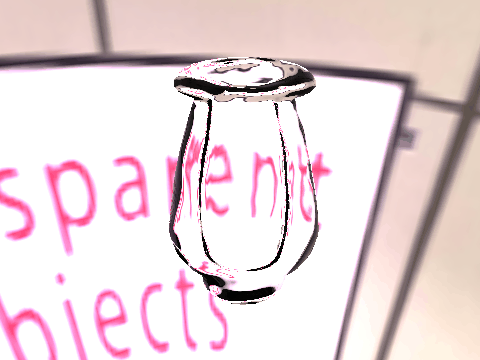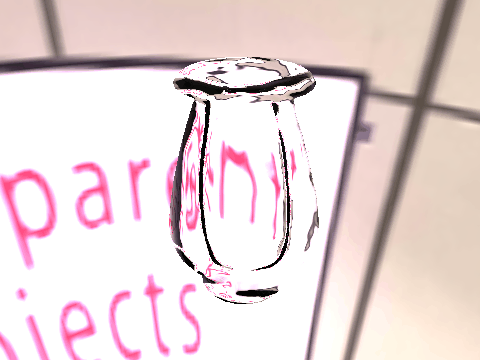 |
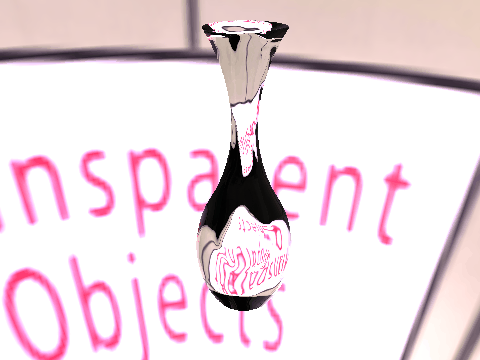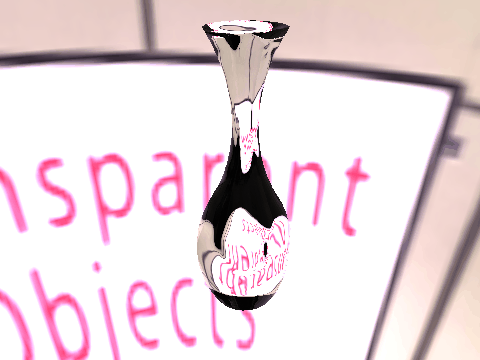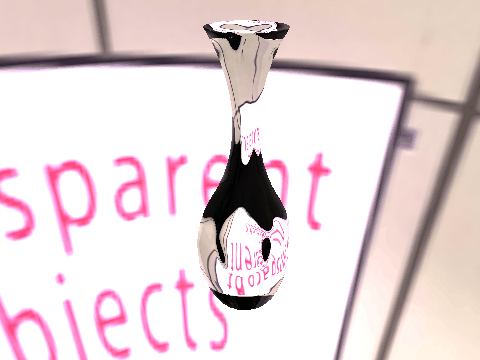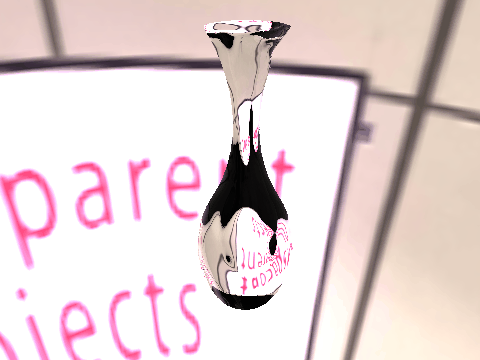 |
 |
 |
 |
| Table 2. Results using real 3D objects. Column A is the input photo. From row 11 to 13 we use the same environment maps in the input and output images. | |||||
| \ | A | B | C | D | E |
| 0 |  |
 |
 |
 |
 |
| 1 |  |
 |
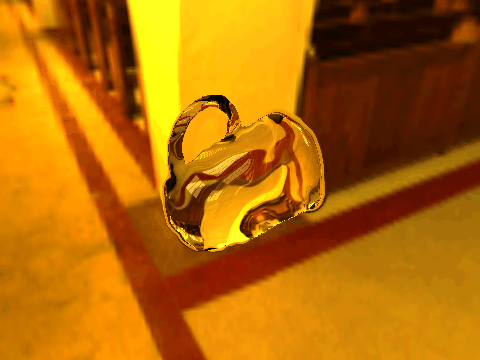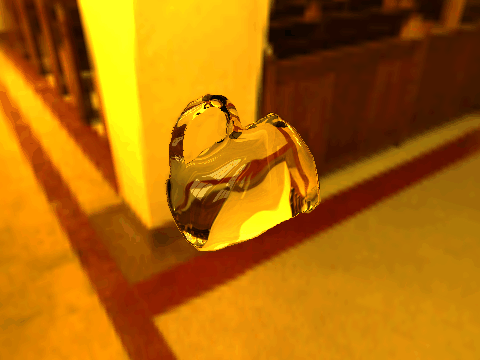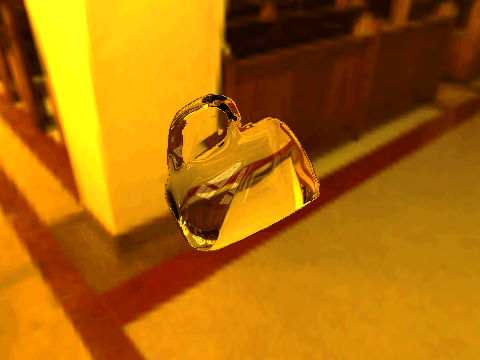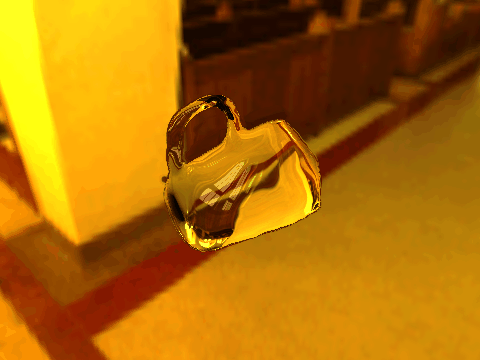 |
 |
 |
| 2 |  |
 |
 |
 |
 |
| 3 |  |
 |
 |
 |
 |
| 4 | .png) |
.gif) |
 |
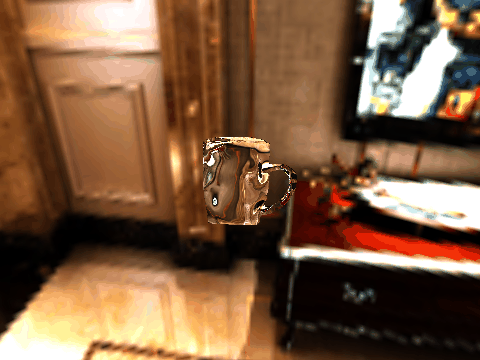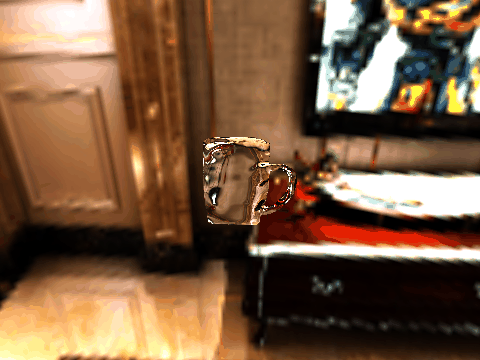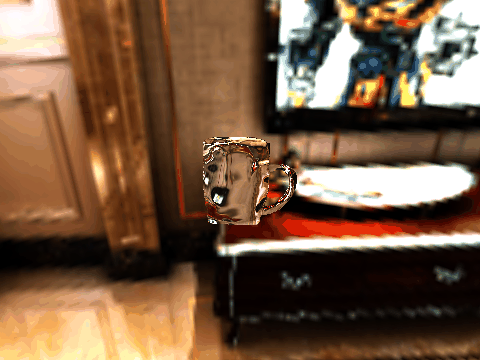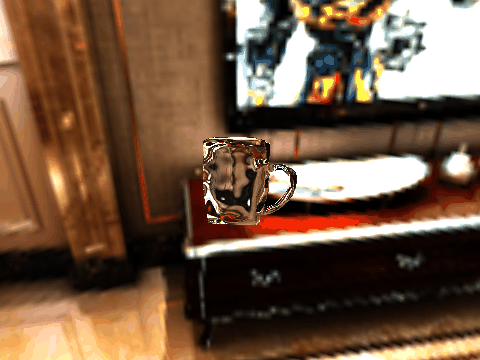 |
 |
| 5 |  |
 |
 |
 |
 |
| 6 |  |
 |
 |
 |
 |
| 7 |  |
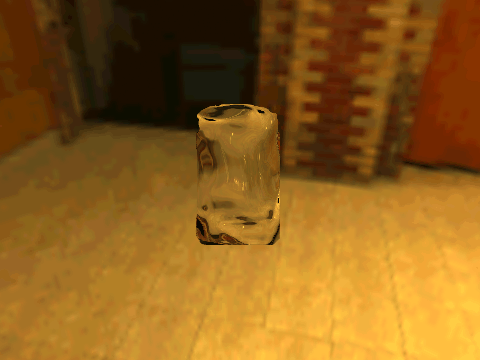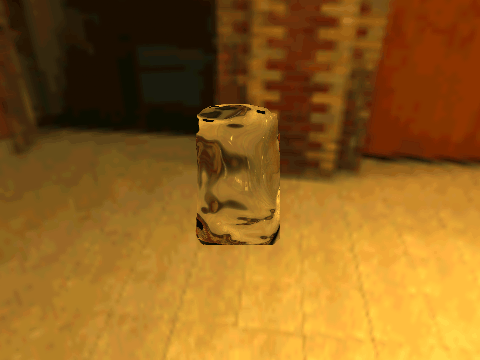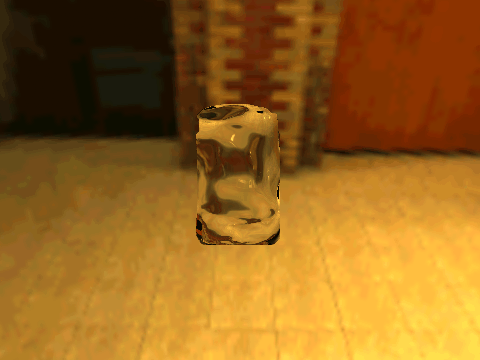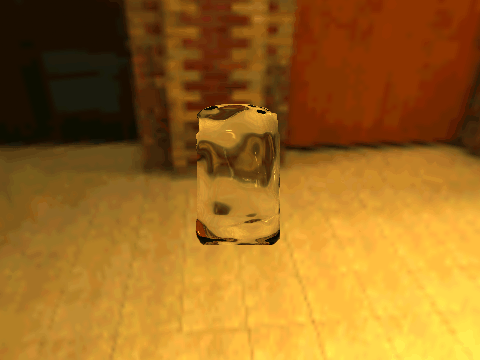 |
 |
 |
 |
| 8 |  |
 |
 |
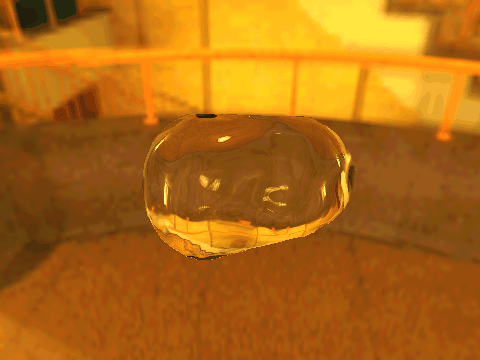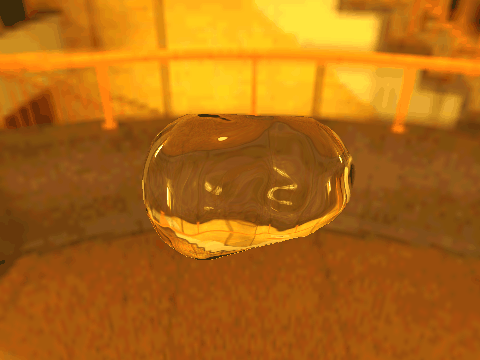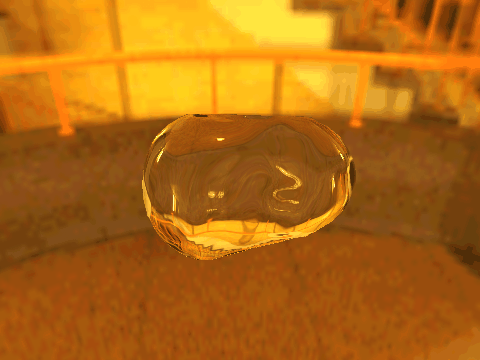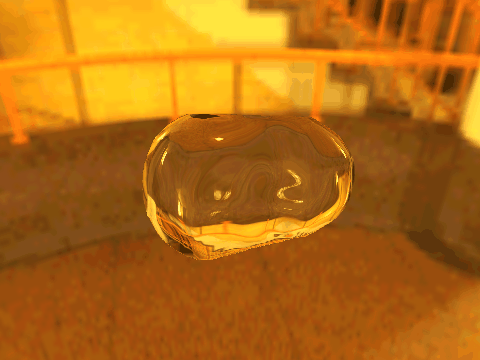 |
 |
| 9 |  |
 |
 |
 |
 |
| 10 |  |
 |
 |
 |
 |
| 11 |  |
 |
|||
| 12 |  |
 |
|||
| 13 |  |
 |
|||
*The tables below are roughly ordered by increasing level of geometry complexity and the amount of self-occlusion, from left to right and top to bottom.
| Table 3. Generated results and ground truths.All results are from -9° to 9°, 19 frames in total. For all images in this table, IoR = 1.4723. | ||||||
| \ | A | B | C | D | E | / |
| Ground Truth |  |
 |
 |
 |
 |
1 |
| Results |  |
 |
 |
 |
 |
2 |
| Ground Truth |  |
 |
 |
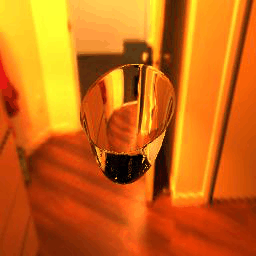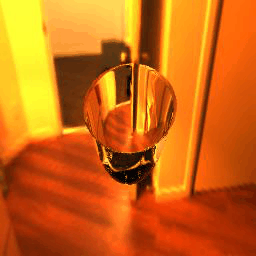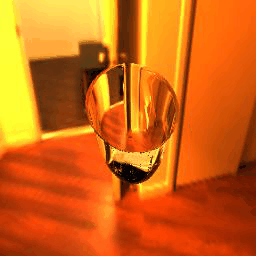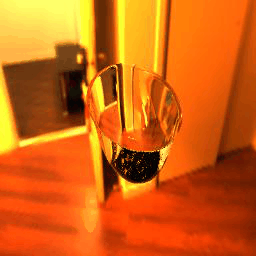 |
 |
3 |
| Results |  |
 |
 |
 |
 |
4 |
| Ground Truth |  |
 |
 |
 |
 |
5 |
| Results |  |
 |
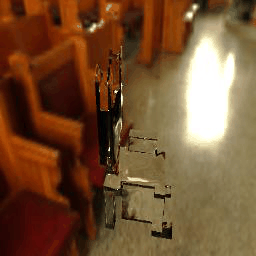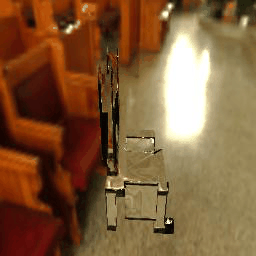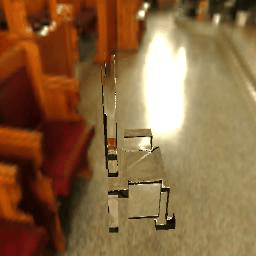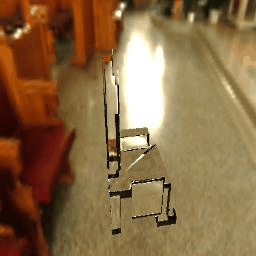 |
 |
 |
6 |
| Ground Truth |  |
 |
 |
 |
 |
7 |
| Results |  |
 |
 |
 |
 |
8 |
| Ground Truth |  |
 |
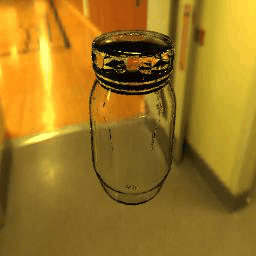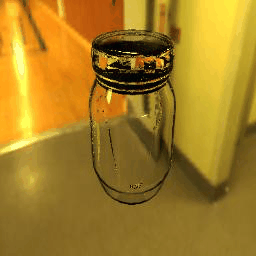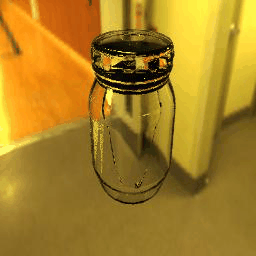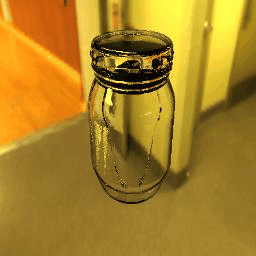 |
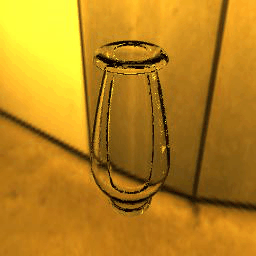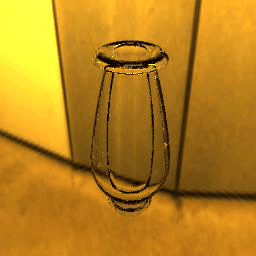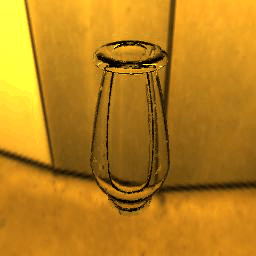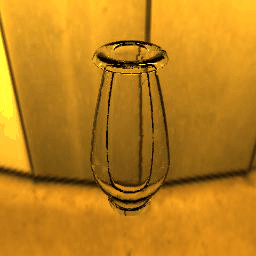 |
 |
9 |
| Results |  |
 |
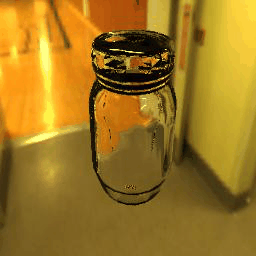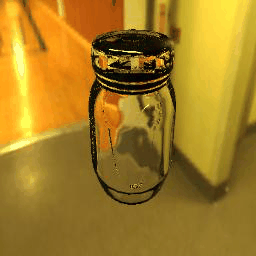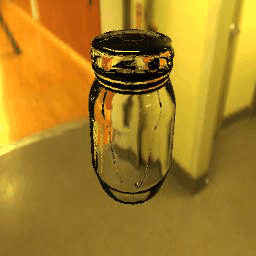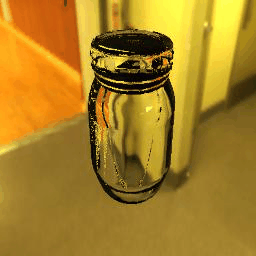 |
 |
 |
10 |
| Ground Truth |  |
 |
 |
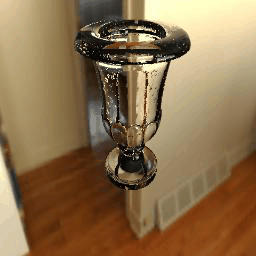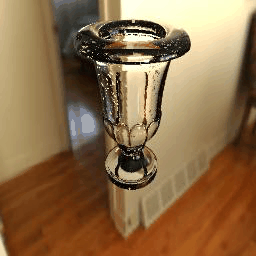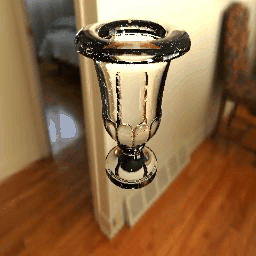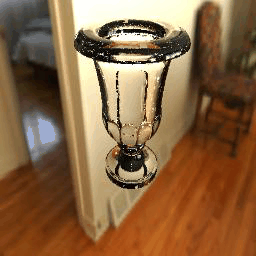 |
 |
11 |
| Results |  |
 |
 |
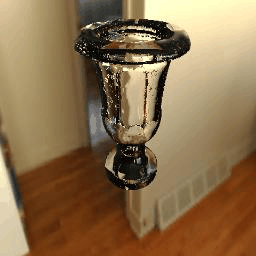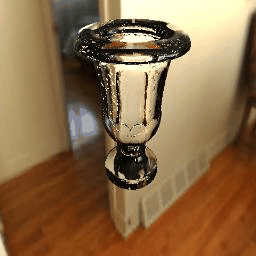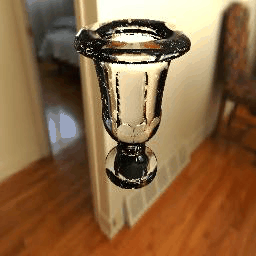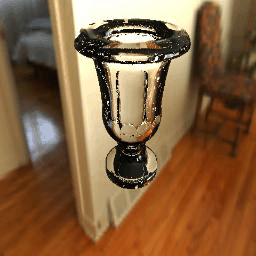 |
 |
12 |
| Ground Truth |  |
 |
 |
 |
 |
13 |
| Results |  |
 |
 |
 |
 |
14 |
| Ground Truth |  |
 |
 |
 |
 |
15 |
| Results |  |
 |
 |
 |
 |
16 |
| Ground Truth |  |
 |
 |
 |
 |
17 |
| Results |  |
 |
 |
 |
 |
18 |
-------------------------------------------------------------------------------------Experiment Results with Increasing IoR-------------------------------------------------------------------------------------
Table 4. Experiments with an increasing IoR at a fixed viewpoint. Each result has 8 frames with 8 IoRs = 1.2, 1.3, 1.4, 1.4723, 1.5, 1.6, 1.7 and 1.8. |
||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
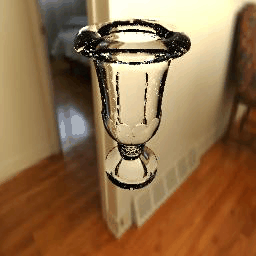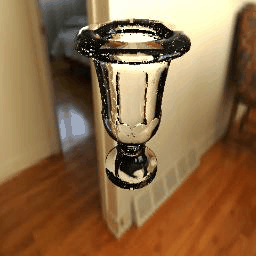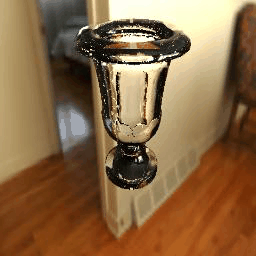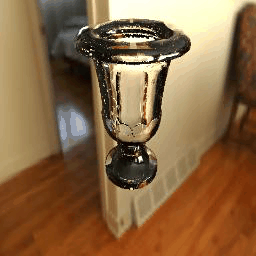 |
 |
 |
 |
 |
 |
-------------------------------------------------------------------------------------Comparsion with Previous Methods-------------------------------------------------------------------------------------
Below we compare our results with 3 existing related methods using the same input perspective and camera poses.
All results are from -9° to 9°, 19 frames in total.
From the left to right are the ground truth, CLDI[1], VAF[2], Synsin[3] and ours.
| Table 5. Comparsion with Previous Methods. | |||||
| Corresponding 3D Shapes | Ground Truth | CLDI[1] | VAF[2] | Synsin[3] | Ours, IoR=1.4723 |
 |
 |
.gif) |
 |
 |
 |
 |
 |
.gif) |
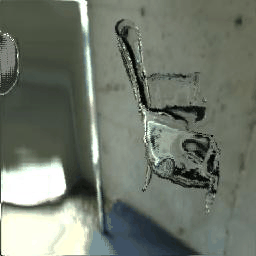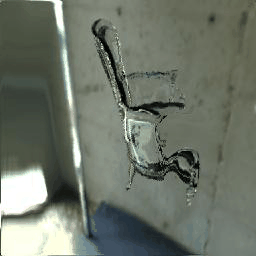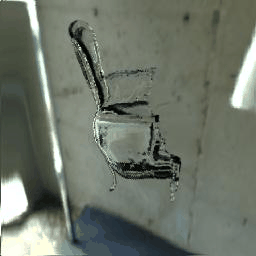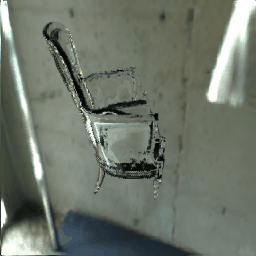 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |